



What happens when a technically AI-ready site still can’t get recognized by ChatGPT, Perplexity, or Gemini—and what it reveals about the gap between being findable and being known
Audit At-a-Glance
| Brand | Stride (stride.page) |
| Category | AI-native software delivery platform |
| Competitors Tested | Jira, Linear |
| Platforms Tested | ChatGPT, Perplexity, Google Gemini |
| Prompts Run | 15 per engine (45 total) |
| Date Conducted | 5 May 2026 |
| Key Finding | A site can score high on technical AI readiness (72) and still score low on actual AI visibility (36)—because the problem starts at identity, not technique. AI couldn’t reliably tell which “Stride” we meant. |
| Headline | Stride is technically ready for AI discovery, but AI doesn’t yet reliably know who Stride is |
Why This Audit Exists
We opened a thread on Reddit with a simple offer: drop your website, and we’ll run a complimentary mini audit showing how AI platforms actually see your brand—then publish the findings.
It isn’t a sales pitch. It’s a public, replicable record of how real B2B SaaS brands perform in AI search, and what separates the brands AI recommends from the brands it can’t place.
Stride was the first to apply. This is what we found.
See the full audit in action
The article below focuses on the key findings, but if you’d like to review the complete scorecard, prompt analysis, and recommendations, we’ve embedded the full report and a video breakdown of the audit.
- 🎥 Audit Walkthrough Video
- 📄 Full Audit Report
Table of Contents
The Distinction That Drives This Audit
One idea does all the work here: readiness is not visibility.
Most SEO audits measure whether a site is built correctly—crawlable, indexed, structured, fast. That’s the input: whether AI can find and parse you.
It says nothing about the output: whether AI actually knows and recommends you when a buyer asks.
So this audit measures both, on two tracks:
The inputs — can AI find and understand you? (Readiness)
- SEO Health reads every technical, on-page, and off-page foundation check.
- AI Readiness reads only the checks that affect AI specifically—crawler access, content structure, schema, third-party mentions.
The output — does AI actually know and recommend you? (Visibility)
- AI Visibility is measured empirically: real prompts on real engines, recording what they say. Not predicted. Measured.
Stride aces the inputs and fails the output. The reason that happens turned out to be more basic than we expected—and it’s the most useful thing in this audit.
The Experiment
Methodology
We ran 15 prompts on each of three engines—ChatGPT, Perplexity, and Google Gemini—in fresh, logged-out sessions to remove personalization bias.
The 15 prompts were split into three deliberate groups:
- Brand Identity (5 prompts) — Does AI know who Stride is when asked directly?
- Category Recommendation (5 prompts) — When a buyer asks for the best options in Stride’s category without naming Stride, does Stride appear?
- Direct Comparison (5 prompts) — Pitted against Jira and Linear by name, how does AI position Stride?
Each response was scored Y (named clearly), P (partial/indirect), or N (not mentioned).
The finding that reframed the whole audit
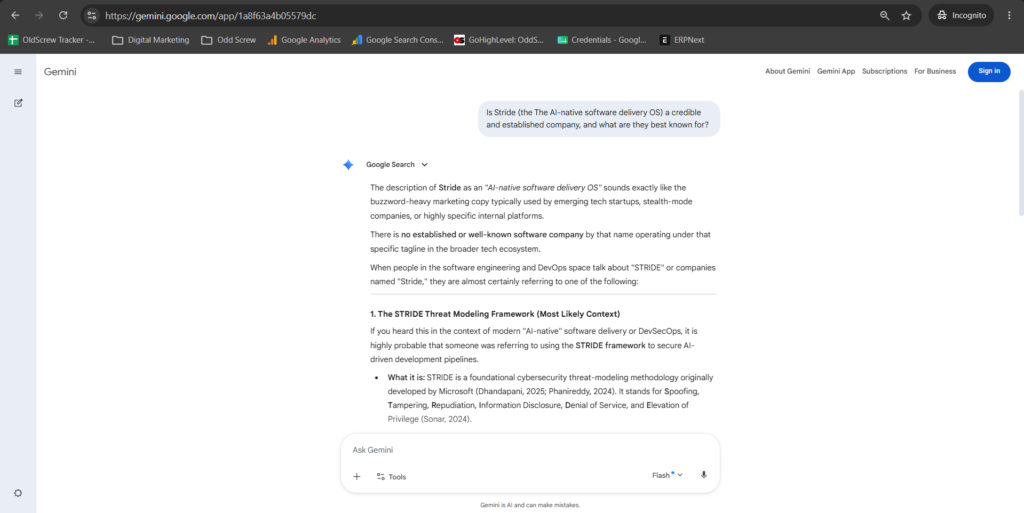
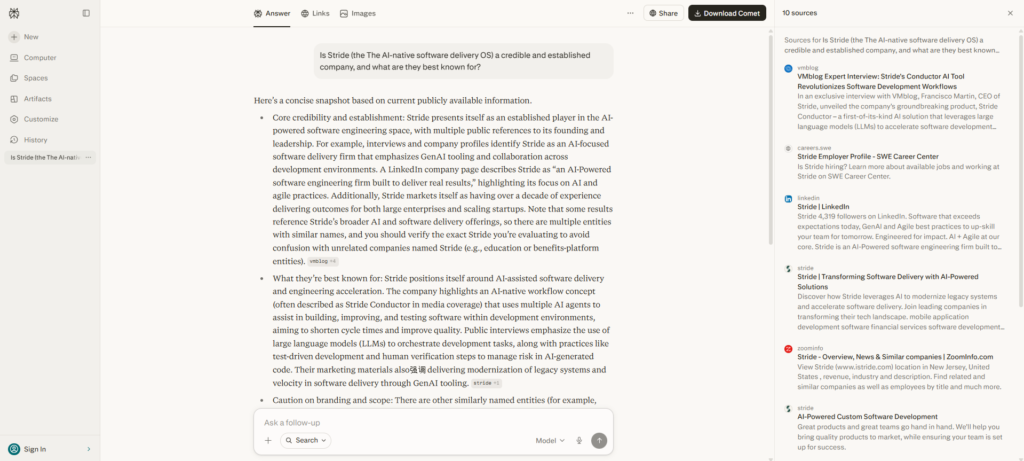
We expected to measure how well AI describes Stride. Instead, we first had to get AI to identify the right Stride at all.
Asked plainly—”What is Stride?”—the engines didn’t return stride.page. They returned other products that share the name: developer tools like Stride.build and strideai.dev, and references tied to Atlassian’s Stride, a team-communication product Atlassian discontinued years ago. Stride.page wasn’t the default answer. In several cases it wasn’t in the answer at all.
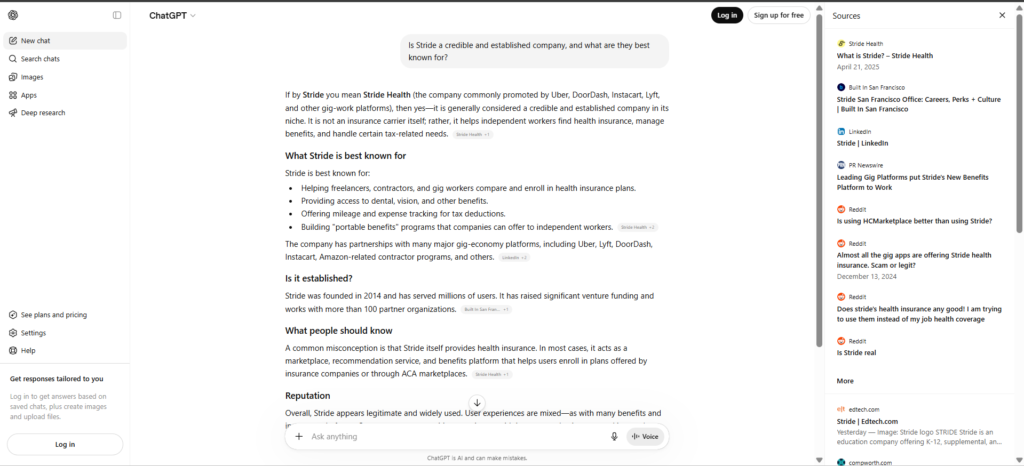
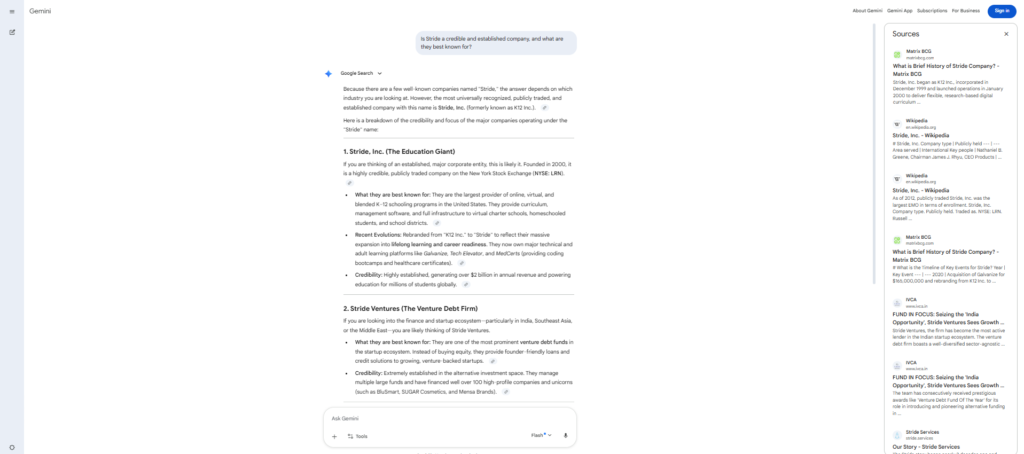
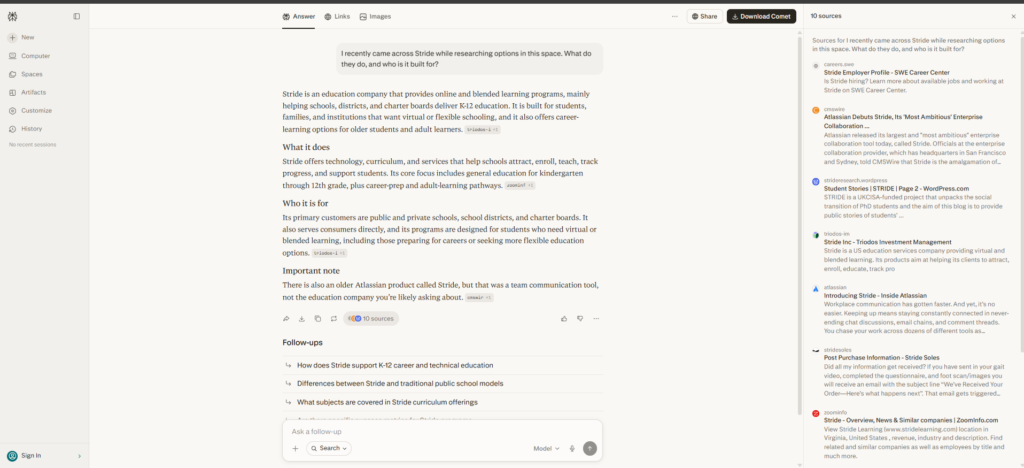
The reason is instructive: those namesakes have something stride.page doesn’t—third-party mentions across the web. AI resolves an ambiguous name by leaning on whichever meaning the web discusses most. The most-cited “Stride” wins the name, and stride.page isn’t it.
To get accurate responses, we had to nudge every identity prompt with a disambiguating descriptor: “Stride (the AI-native software delivery OS).” Only then did the engines reliably land on the right company—and even then, not always.
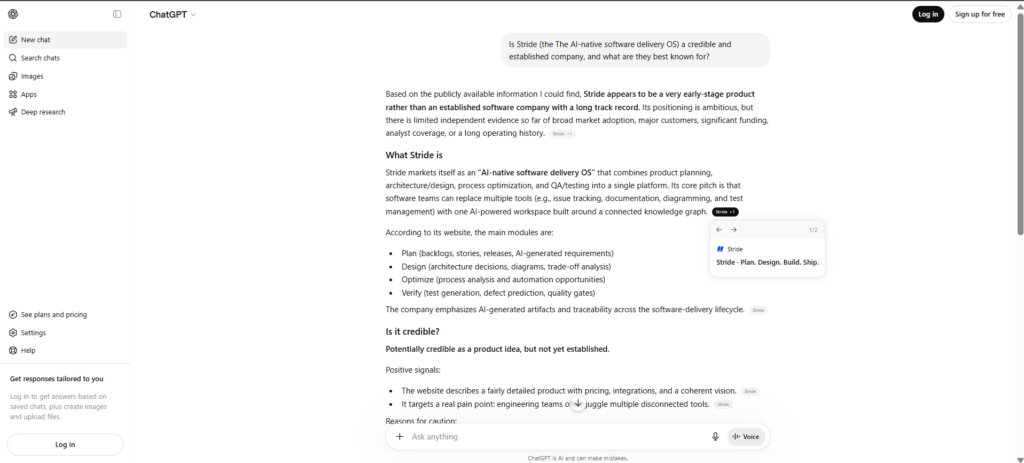
This is the real story of the audit. Buyers don’t add descriptors. If AI can’t resolve “Stride” to stride.page on its own, the brand has a recognition problem that sits upstream of everything else.
The Results
Readiness (the inputs)
| Lens | Score | Read |
| SEO Health | 69 / 100 | Partial — key fundamentals need work |
| AI Readiness | 72 / 100 | Strong — solid AI-readiness foundations |
Technically, Stride is in good shape. 20+ AI crawlers are explicitly allowed in robots.txt. The site is server-rendered, mobile-friendly, indexed across 350+ URLs, and carries valid schema. AI can find and parse Stride without trouble.
Visibility (the output)
| Metric | Score | Read |
| AI Visibility | 36 / 100 | Emerging — occasional mentions only |
| Engine | Score (of 15) |
| ChatGPT | 8 |
| Gemini | 8 |
| Perplexity | 5.5 |
A 72-point input producing a 36-point output is the headline number. But the why lives in the identity prompts, not the category ones.
The SEO Foundations Are Strong—But Not Perfect
Before we get into AI visibility, it’s worth noting that Stride’s traditional SEO foundation is generally solid.
The site is crawlable, mobile-friendly, server-rendered, and indexed across hundreds of URLs. AI crawlers are explicitly allowed, schema is present, and the information architecture is well structured.
The audit also surfaced a handful of opportunities:
- Homepage title tags are highly brand-focused but don’t strongly reinforce category relevance.
- Performance could improve through edge caching and CDN optimisation.
- The sitemap includes utility URLs such as login, registration, status, and changelog pages that don’t contribute to organic discovery.
- Organization schema could better reinforce the Stride brand entity by separating the product brand from the legal business entity.
None of these are major blockers, but together they represent relatively quick wins that would strengthen both search visibility and AI understanding.
What the Prompts Revealed
Identity is the bottleneck
Once we supplied the descriptor, ChatGPT and Gemini could describe Stride, its pricing, and reviews reasonably well. But the need for that descriptor is the finding. Even with it:
- ChatGPT identified the company correctly.
- Gemini identified it correctly.
- Perplexity still could not reliably place the right Stride.
When the most basic question—who are you?—needs a hint to answer, and one of three engines fails even with the hint, every downstream question is built on sand.
Why we’re not dwelling on the category result
Across the five category prompts—”What are the best AI-native software delivery platforms?”—Stride scored N on all three engines. It’s a real gap, but on its own it isn’t the interesting one: most brands fail to appear in category recommendations when their name isn’t in the prompt. That’s the hardest tier of AI visibility, and a low score there is normal, not diagnostic.
What makes Stride’s case different is why the category result is zero. It isn’t that AI weighed Stride against rivals and passed. It’s that AI doesn’t yet have a stable, single understanding of who stride is. You cannot be recommended for a category if the engine can’t first resolve your identity. Category visibility is a symptom here; identity is the cause.
Comparisons stay neutral
When asked to compare Stride against Jira or Linear, AI engines generally remained neutral. Instead of picking a winner, they matched each platform to different use cases and team requirements—a pattern increasingly common across AI-generated software recommendations
Why the Gap Exists
Two causes explain the collapse from 72 to 36, and identity sits above both.
1. A generic name with no external footprint to claim it
“Stride” is a crowded name. AI resolves crowded names by deferring to the most-cited meaning—and the citations point to other Strides, not stride.page. This isn’t a technical fault on the site; it’s the absence of enough distinctive, repeated association across the web to make stride.page the default “Stride.”
2. No third-party validation
This is the deeper cause, and it’s what feeds the first. We searched for independent signals and found almost none:
- Review platforms: not listed
- Reddit, forums, press, analyst coverage: one stray mention, nothing more
- Backlinks: Domain Rating 0, 42 referring domains, mostly from link networks rather than editorial sources
It shows up directly in how AI sources its answers about Stride: overwhelmingly from stride.page itself. When AI discusses Jira or Linear, it pulls from review sites, analyst reports, case studies, press, and community threads. For stride.page there’s little else to pull from—so AI can neither confidently identify it nor recommend it.
3. The Perplexity tell
One detail confirms the diagnosis. Perplexity—the engine that searches the live web in real time—scored lowest (5.5), below the two engines relying on older training data. If real-time search surfaces less, it’s because there’s little indexed, third-party web presence to surface. The problem isn’t AI’s memory. It’s the absence of an external footprint.
What This Reveals for B2B SaaS
Stride is one brand, but the pattern generalizes.
Identity comes before everything. Recommendation, comparison, category authority—all of it assumes AI can first resolve your name to you. If your brand name is generic and under-cited, AI will quietly hand your identity to a better-documented namesake, and you’ll never know why your visibility is low.
Third-party mentions are how AI settles ambiguity. A name isn’t owned by whoever registers the domain; in AI’s eyes it’s owned by whoever the web discusses most. Reviews, press, community threads, and editorial coverage aren’t just trust signals—they’re how you win your own name.
Technical readiness creates the foundation, not the outcome. Stride scored well on AI readiness because the site is crawlable, indexed, structured, and easy for AI systems to understand. But readiness alone doesn’t guarantee visibility. AI can understand a brand and still choose not to surface it.
SEO still matters—but for a different reason. The audit uncovered opportunities around metadata, schema implementation, sitemap prioritisation, and performance optimisation. These won’t solve the visibility challenge on their own, but they strengthen the signals search engines and AI systems rely on when building confidence in a brand.
Visibility is ultimately an authority problem. Once the technical foundation is in place, the next challenge shifts beyond the website. The brands that get cited, mentioned, reviewed, and discussed are the brands AI learns to trust—and eventually recommend.
The Priority Fixes
1. Win your own name first. Build distinctive, repeated association between “Stride” and stride.page across the web—consistent descriptor, consistent entity naming, presence on the platforms AI trusts—so engines resolve the name without a buyer’s help.
2. Build third-party validation. Get listed on G2 and Capterra. Earn press, analyst, and community mentions. Publish customer stories that live beyond your own domain. Give AI external sources to cite—the same sources that will settle the name in your favor.
3. Then pursue category ownership. Only once identity is stable does category-defining content do its job. Trying to own a category before AI can reliably identify you is building on a foundation that isn’t set.
The order is the point. Identity and validation are prerequisites; category authority compounds on top of them.
Access the Full Audit
This article highlights the key findings, but the complete audit includes the full scoring framework, prompt-by-prompt analysis, platform observations, and detailed recommendations.
- 🎥 Watch the Audit Walkthrough
📄 View the Full Audit Report
About This Series
This is the first entry in our AI SEO Mini Audit Series—complimentary, published audits for brands who request one. Each mini audit is a snapshot: the foundational, high-signal checks plus a 30-prompt visibility run. The full engagement scores every check across a complete framework, tracks per-platform citation trends monthly, and ties findings to a 30/60/90 roadmap.
Want one? Drop your website and two competitors on our Reddit thread.

